Мой день по анализу данных с использованием Claude
Решил рассказать, как я использую Claude в своей работе. Сейчас я занимаюсь тем, что встраиваю Data Driven процесс в работу компании Larixon, мы выпускаем Classifields в разных странах, моя же задача связать метрики, с которыми работают продуктовые команды, которые заточены в том числе, на то чтобы сделать счастливыми наших пользователей, которые не платят нам деньги, с метриками, которые связаны с юнит-экономикой, финансами и в конечном счете с нашей прибылью.
Как я работал раньше?
Ранее, я занимался тем, что руками изучал какие есть метрики, строил дерево метрик, модель юнит-экономики и потом смотрел, как объяснить команде, которая повышает удобство поиска объявлений на площадке, что ее продукт должен приносить деньги компании.
Трудность была связана с тем, что команд много, сейчас я оперирую 34 командами (деление на команды условное, но столько людей, которые отвечают за метрики у меня в пуле), метрик еще больше, речь идет о сотнях, продуктовые команды работаю с более чем 150 метриками, а дерево метрик, где размещены только метрики юнит-экономики и продуктовые метрики связанные с метриками юнит-экономики насчитывает больше 180 узлов.
В ручную держать в голове все эти связи то еще испытание. А отслеживать взаимное влияние, прогрессы и т.д. скорее не возможно.
Calude
С появлением агентов, работу можно автоматизировать, например, рутину по поиску связей между одним документом (список задач в продуктовых командах) и дереве метрик, можно отдать LLM, и она в целом хорошо, а главное быстро справиться с этой работой.
Для этого просим агента взять файл и связать его с другим файлом, в целом промпт это отдельное знание, и многие даже просят одного агента подготовить промпт для другого агента. Но в любом случае, бездушная машина быстро выполнит задачу, предварительно оценив ее в человеко-часах, как примерно 5-7 дней плотной работы, но традиционно справиться за 20 минут. В качестве артефакта у вас появится MD файл, который еще нужно прочитать.
Некоторые просят другого агента прочитать этот файл и сделать выжимку, которая опять превращается в MD файл. В итоге, вы быстро обрастаете большим числом разнообразных MD файлов, а в моем случае, так как я работаю еще и с финансовыми отчетами, то и с большим числом CSV файлов. А так как мой агент продвинутый, то я получаю ECSV файлы, которые еще надо уметь открывать, хотя это просто CSV с комментариями.
В рамках своих задач я очень быстро оброс кучей таких файлов и легче не стало, а только тяжелее, раньше я мог контролировать продвижение к цели сложностью, то сейчас продвижение к цели тормозится именно мною, из-за неспособности прочитать быстро большое число материалов, прочитать, понять и сделать выводы.
Как я работаю сейчас?
Сейчас моя работа изменилась. Первым делом я начал использовать loOom специальную утилиту, которая фактически является прослойкой между мной, данными и агентом.
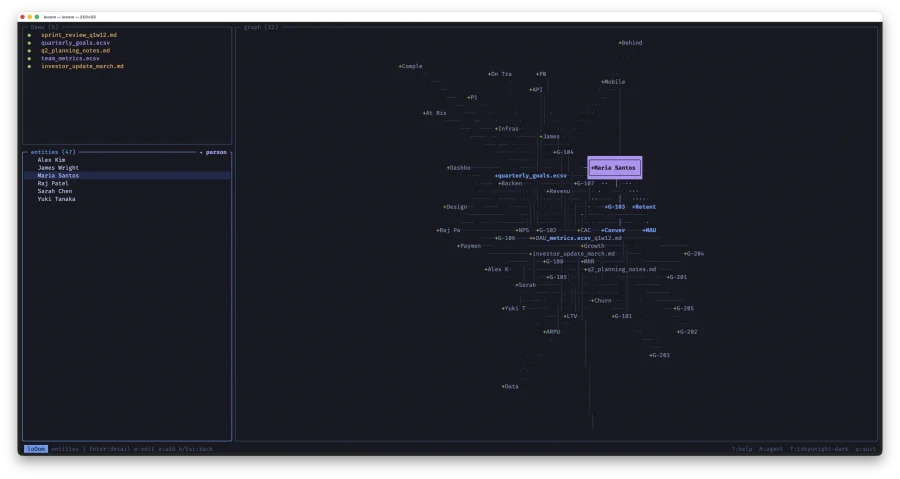
Что делает loOom? Первым делом, она ведет список всех документов, которые создает агент. Кроме того, она умет настраивать агента, в моем случае Claude, для работы с собой. Это значит, что когда агент создает вам артефакт (MD, CSV, ECSV) он сразу настраивает loOom для того, чтобы loOom вытащил из артефактов все полезные сущности, разместил их на графе и связал.
Таким образом, я получаю возможность, быстро увидеть, а что за артефакты подготовил мне агент. Кроме того, loOom умеет вызывать агента изнутри и передавать ему контекст. В итоге, я работаю с агентом изнутри loOom и поддерживаю агента в контексте. Фактически loOom выступает как внешняя память для агента.
Кроме того, loOom может работать и сам по себе, он просто анализирует файлы, находит между ними связи и строить граф, вы можете находить цепочки связей, и смотреть как один сущности связаны с другими. При этом вам не нужно тратить свои токены для получения всего этого.
Теперь мой процесс такой:
запустить loOom
найти интересующую меня сущность, например, из финансового отчета, я вижу, при общем спаде Revenue, рост продаж по направлению.
сразу могу увидеть какие другие сущности связаны с этой метрикой
какие люди отвечают за связанные метрики
если что-то не ясно, я нажимаю А и передаю контекст в агента, переключаюсь в него; агент же уже готов, он в контексте и я могу получить дополнительную информацию
в результате, я получаю новый MD файл, и агент знает, что его надо разместить на графе
после возврата из агента в продукт, я обновляют граф сущностей и...
перехожу к следующей задаче.
Использование агентов сильно ускорило работу по анализу данных, а появление решений, которые позволяют не утонуть в объеме информации, сделало работу проще.
Практические методы юнит-экономики и финмоделирования
50€/год
менее 1€ в неделю · оплата раз в годА ещё: выбор темы оформления, настройка шрифта, печать статей и увеличение изображений.
Для доступа к материалам оформите подписку.
Если вы уже клиент, то просто входите.
* – оплата через Boosty позволяет оплачивать картами Мир, оплата через Stripe для международных карт Visa, Mastercard и т.д.
мы не храним ваш email, а только зашифрованный hash, что повышает безопасность вашей почты.